网页电影
日期:2023年08月31日 14:48 浏览量:1
爬取网页(https://movie.douban.com/top250)上的电影信息
- 网页分析https://movie.douban.com/top250,属于静态网页,我们所需的数据资源在网页源代码中呈现。因此,我们只需获得网页html代码进而解析取出其中某些结点(本次简单获取电影名称和引述)就可以获得想要的数据。
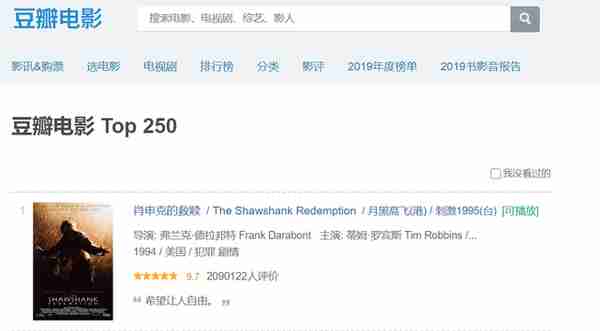
网页效果
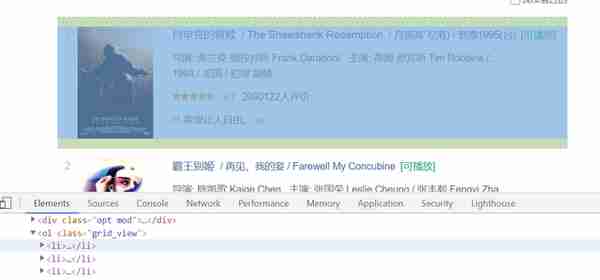
每个li标签中有一部电影
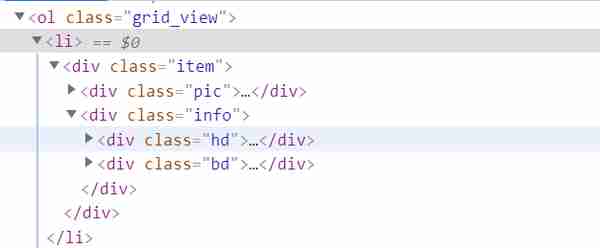
我们获取每个li,再对其子节点进行查找可以得到想要的信息。
- 工作流程:获取网页 ->解析网页 ->打印或保存信息
- 依赖工具:requests、BeautifulSoup、time,Pycharm或者文本编辑器、浏览器
- Python代码:
# -*- coding: utf-8 -*-# @Author: 搞爬虫# @Date: 2020-07-26 09:38:07# @Last Modified by: 搞爬虫# @Last Modified time: 2020-07-26 14:54:25#库引入import requestsfrom bs4 import BeautifulSoupimport time定义获取html文档的函数# (参数:)可以指定参数类型def getHtml(i:int,startUrl:str,headers:dict): text = '' #每一页URL的区别在于start(如:第二页URL:) # https://movie.douban.com/top250?start=25&filter= ,以此类推 url = startUrl+'?start=' + str(i*25) try: r = requests.get(url,headers = headers,timeout=8) if r.status_code == 200: return r.text except: print("failed to get html") return ""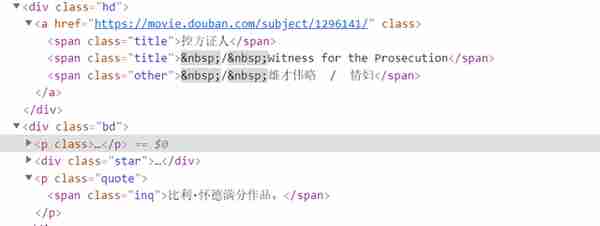
#定义解析网页的函数def parseHtml(text:str,temp:dict) : if text != '': soup = bs(text,'lxml') info_div = soup.find_all('div',class_='info') for eachMovie in info_div: ls = [] #这里用名称作为字典的键,其他信息存放在列表中作为值 info_hd = eachMovie.find('div',class_='hd') info_bd = eachMovie.find('div',class_='bd') #电影名称文本 name = info_hd.a.span.text.strip() #电影简述文本 quote = info_bd.find('p',class_='quote').span.text.strip() ls.append(quote) temp[name] = ls return temp#定义控制台打印信息函数def printContent(Info:dict): if Info is not None: count = 0 print("{:20}\t\t{:10}\t".format("电影名称","电影引述")) #格式化打印 #获得每一个键值对 for key,value in Info.items(): if count == 10: print('') print("============================================") count = 0 print("{:12}\t\t{:^20}".format(key,value[0])) #字典的值是列表类型 count += 1 else: print('no data')#主函数def main(): #这里可以打开开发者工具查看正常访问页面的请求头 #网页不涉及重要信息,我们只进行少量的爬取,不进行伪装也可以 headers = {'user-agent':'Mozilla/5.0'} result = {} startUrl = "https://movie.douban.com/top250" num = input('要爬取多少页(1~10)') for i in range(eval(num)): text = getHtml(i,startUrl,headers) time.sleep(2) #可以间断访问 result = parseHtml(text,result) printContent(result)if __name__ == '__main__': main()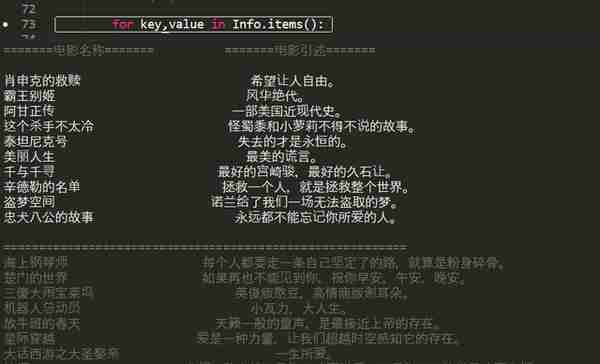
运行结果
改进过后可以显示电影的具体信息。完!
推荐阅读
相关资讯

-
黑色的招商信用卡(黑色的招商信用卡图片)
2023-08-31
).span.text.strip() ls.append(quote) ...

-
万达期货官网(万达期货官网客服电话)
2023-08-31
).span.text.strip() ls.append(quote) ...

-
建行港币兑换人民币(建行港币兑换人民币流程)
2023-08-31
).span.text.strip() ls.append(quote) ...

-
九欧是多少人民币(9欧元等于多少英镑)
2023-08-31
).span.text.strip() ls.append(quote) ...
-
临沂做期货去哪(临沂做期货去哪做)
2023-08-31
).span.text.strip() ls.append(quote) ...

-
目前中国黄金价格(目前中国黄金价格走势图)
2023-08-31
).span.text.strip() ls.append(quote) ...